What changed since the first alpha?
First of all, there was a number of quite important changes on the organizational level. Indeed, we decided to adopt a Code of Conduct, to make sure contributing to Plume is a pleasant experience for everyone. If you are curious, you can read it here (it is based on the Contributor Covenant Code of Conduct).
We also opened a Loomio group to discuss non-technical issues. Loomio is a tool designed to discuss and vote on specific topics. It only requires an email address to participate, and we would be happy to welcome you to our debates. If you wante to help Plume, but don't have much time or lack technical skills, participating on Loomio is a great way to contribute.
Among other things, we used Loomio to choose the new Plume logo, and after a poll, @trwnh@mastodon.social's proposition was chosen. It will now be displayed by default on all the instances and used for branding on other websites (Matrix, GitHub, etc). However, we plan to integrate other logos as well (so that the other proposition aren't lost) and we will add an option for you to choose the one you'd like to use on your instance.

Plume also has a website to introduce the project, host its documentation and contribution guides (this last page is based on Funkwhale's page).
But what about Plume itself? As you can imagine, since the first alpha was published, a lot of changes have happened.
Let's start with the bug fixes. There was a lot of them (we are still in an alpha phase after all), but the most important ones are probably the following:
- We now handle long articles better
- Articles and blogs without any authors (when the last of them deletes their account) are now deleted to avoid crashes because of articles or blogs without authors
- We have addressed an important security issue in the way we check who has the right to do an action or not (for instance, previously, it was relatively easy for an attacker to delete a picture you uploaded)
- @vbrandl also fixed a bug that was breaking the notification page when a comment was deleted
Most of theses changes are not visible (because it works as expected now), but will noticably improve your experience with Plume (as well as your security).
There was also some design updates: @dfeyer@social.ttree.ch improved the contrast of input fields, and improved the title's style so that they are readable even when wrapped on multiple lines (and he started to work on more important design updates, that may come in the next release). Plume should also work better on small screens now.
On the federation side, @KokaKiwi and @FDB_hiroshima committed quite a lot of bug fixes. I (@Ana) also made a lot of changes to the code that handles incoming activities, making it easier to maintain and more compliant with the ActivityPub specification. The federation should be a lot more reliable now! @FDB_hiroshima also implemented two very important security and privacy related features: signature verification, to make sure the activities we receive from other instances are indeed coming from these instances, and blind key rotation. The NodeInfo, that gives information about a Fediverse instance for websites like the-federation.info, was also updated by @0x1C3B00DA@edolas.world to support both the version 2.0 and 2.1 of the standard.
@mareklach@mastodon.xyz also made a lot of changes to the phrasing used in the interface. Thanks to him, the English translation of Plume is now nicer to read. The term "follow" was also replaced by "subscribe" which is less person-centric and more adapted in the context of blogs.
The translations were also updated: Plume is almost completely translated in ten languages now!
I want to thank @alangarciar, @amikigu, @ardydo, @khannaankitaa, @ButterflyOfFire@mstdn.fr, @Devil505, @faho, @fitoshido, @FDB_hiroshima, @heldergg, @ida27, @Lacrymology, @m4sk1n@101010.pl, @ManuelFranz, @mareklach@mastodon.xyz, @metalbiker@ins.mastalab.app, @Moutmoutausore, @netopyrr, @ryonakano, @Silviu200530, @Swedneck, @UniqueActive, @wilPoly and @xosem@mstdn.io (that's a lot of people!) for their help. By the way, we are now using Crowdin to translate Plume, which makes it much more convenient when you are not familiar with GitHub.
Of course, we implemented a bunch of new features these last months! Among them:
- You can now delete and edit blogs
- Articles can now contain hashtags, which are correctly federated to other ActivityPub platforms
- Articles can have cover images which will make them standout more in the article listings
- View who is subscribing to a user by going to their profile
- Your password can now be reset, in case you forgot it
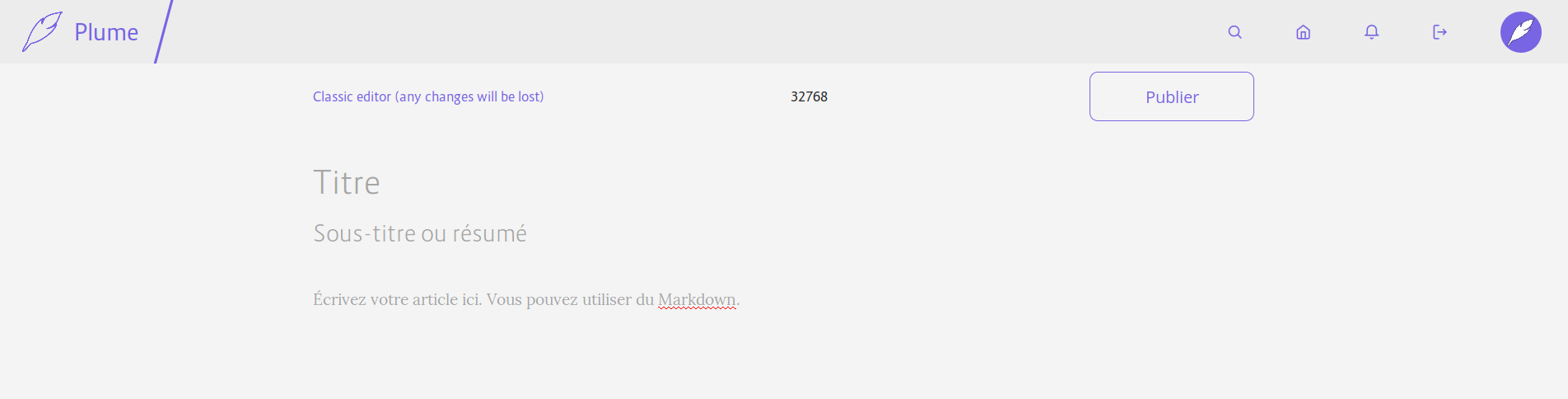
A new editor, that should be more pleasant to use was also introduced! It is for the moment quite basic, but we plan to add a lot of features to make writing articles with Plume easier, even if you don't know Markdown.
We also improved integration with other services. Microformat tags were added making it easier for external apps to display Plume articles in their interface. RSS feeds are also more discoverable now (a little link was added on blog and user pages), and a bug that broke them in some case was fixed. OpenGraph metadata were also added, so that when you share a Plume article on another website, a nice preview card can be displayed.
The comments improved a lot too. It is now possible to delete them. We also correctly handle comment visibility from other instances, even if it is not yet possible to change it when commenting from Plume. Content warnings (as they are called in Mastodon) are also now supported in comments.
We also added features that will please people hosting an instance. First of all, thanks to @hirojin@dev.glitch.social it is now possible to use SQlite instead of PostgreSQL as a database engine. We also replaced the not so well working "setup script" that asked you questions to help you setup your instance with a command line tool, called plm, that has various commands to manage your instance. The default license for new instance was also changed to CC-BY-SA, which is a better default than CC-0. And finally, it is possible to choose which logo to use for your instance from the configuration.
A REST API to create articles was also added. We built a command line tool, called amsterdam (thanks @Doshirae@social.wxcafe.net for the great name) on top of this new API to import posts stored on your computer.
Finally, maybe the biggest feature in this release, a search engine was added to Plume!
It has been implemented with the amazing tantivy crate, which is working very well and barely consumes any resources. If you want details about the technical aspects of this feature, you can read this article.
On the technical side, a lot of changes happened too. Thanks to @kemonine@social.holdmybeer.solutions and @eliotberriot@mastodon.eliotberriot.com our Docker files are working great, even on ARM, the Docker image became smaller and is now published in the Docker registry (and in Lollipop cloud's one for ARM builds).
The styling is now done with SCSS, which is much more convenient than regular CSS.
We also added some constraints at the database level (there were almost none before), to avoid saving invalid data.
We try to take advantage of Rust power as much as possible. For that purpose, we reworked our error handling to make it use the powerful Result type instead of making Plume crash on error. We also converted our front-end code from JavaScript to Rust thanks to WebAssembly. It means we can now easily share code between the back-end and the front-end if needed. Our templates have also been rewritten using ructe, which is a crate that compiles your page templates to Rust functions, guaranteeing their correctness before Plume starts, and improving performances.
A feature that recently landed in Rust is what we call proc-macro. They are special functions that can transform some code to something else in very powerful ways. I used this feature to create a few proc-macro that automatically generate translation files and use them in Rust apps. If you are curious, here is the repository.
We also started to write more tests, and even if the coverage is still very low (around 30% at the moment), we are making progress, and I hope we can be near to 100% of tested code for the first real release. @FDB_hiroshima also migrated our Continuous Integration to Circle CI, which is much more faster than Travis CI.
How to try this new version
If you want to give this new version a try, Fediverse.blog is already up-to-date. Otherwise, just give some time to your instance admin to update. 😄
If you are an instance admin, and you want to update or install a new instance, please refer to the release notes on GitHub.
What will come next?
Even if we made a lot of progress, tons of features are still missing for Plume to be really usable. I can't tell for sure what will be next, but I would like to work on multi-authors blogs and articles, and on moderation tools, because the one we currently have are too basic to be really useful. @hirojin@dev.glitch.social is also working on custom domains for blogs, so that may be in the next update!
However, I don't know how much I will be able to contribute in the following months, because my exams period will start soon, and I will have less time to give to Plume. Fortunately, I'm not the only person working on Plume.
I probably forgot a lot of people in this article, and I don't have everyone's real @, I'm sorry. I would like to thank everyone who made this release possible (even if your name was not cited here). Thank you! 💜
]]>
